Bluespec Extension for VS Code
If you came here from the Marketplace page or the GitHub repo, this is a blog post where I discuss my extension in greater detail.
Overall Demo
Overview
I wrote an extension to bring high-quality syntax highlighting to Bluespec (and Minispec) on Visual Studio Code. I believe this is the first extension to do so.
It was a major goal for me that the syntax highlighter should be as good as the syntax highlighter for any mainstream programming language available for VS Code. I think, short of practically baking in a compiler, this extension meets that goal.
In terms of development, I followed the VS Code Syntax Highlight Guide and the TextMate manual page for grammars. Both really have a lot less documentation than they should, and I detail my journey below.
I discuss why I wrote the extension for VS Code, the extension’s Action Analysis Engine, the focus on external consistency with syntax highlighter standards across languages, and added support for fenced code blocks in Markdown.
I talk a bit about the development process, including some tricks I used to make the effort more palatable.
I also briefly discuss the outreach I’ll do to inform people of the extension, and future plans I have with it.
See the source code for my extension in my GitHub repo, or the extension’s page on the VS Code extensions Marketplace.
Also see my Bluespec lexer that I built for Rouge, which renders Bluespec not for VS Code but for the Jekyll site generator, which I use to make this website.
Neither I nor this extension are affiliated with Bluespec Inc.
Why?
I think I would be on the fence vis-a-vis writing an extension if I was the only one to use it, but I know there’s major demand for quality Bluespec (and Minispec) syntax highlighting in VS Code.
I don’t know how many people use Bluespec in industry, but I do know that hundreds of college students are being educated each year with Bluespec at MIT and a few other colleges. With the overwhelming popularity of VS Code, the chances are that anyone learning Bluespec will be doing so in VS Code.
According to annual surveys by Stack Overflow, 3 in 4 developers use VS Code, and it’s been true for several years. Back in 2016, the highest majority any editor got was 35%. This extreme consolidation is especially reflected in the classroom.
When I was taking 6.192 at MIT with 30 other students earlier this year, many of us were using VS Code with barebones, one-step-above-nothing Bluespec syntax highlighting from the extension Marketplace. We would’ve appreciated anything better. I bet the same is true of the 500 MIT students each year taking 6.191 using Minispec. Such an audience is worth the effort. If there are other users, then that’s all the better.
It’s tough enough learning and practicing hardware design and computer architecture. Tools like good syntax highlighting can make things a little more comfortable, both for students in the classroom and developers everywhere else.
Selected Features
The extension’s true value is in its highlighting quality and coverage, but I would also like to highlight a few features.
Action Analysis Engine
Like with the Bluespec lexer I wrote, I included functionality for distinguishing between pure functions and state-changing expressions. Since I was putting the extension onto the Marketplace, I snazzily branded it as the Action Analysis Engine.
When I discuss Action Analysis (under a generic name) in my post about my Bluespec lexer for Rouge, I discuss the complicated relationship between actions and the compiler scheduling. An improved version of Action Analysis may further distinguish between:
- struct member accesses (which have no impact on scheduling or critical path),
- conflict-free (CF) reads (which truly have no impact on scheduling, though they may affect critical path),
- non-CF reads (which affect scheduling and path)
- Actions/ActionValues, (which affect scheduling, path, and state).
For a syntax highlighter, these represent a lot of potential subtokens that would need to be themed. I don’t know if the default VS Code palettes support that level of granularity. And before that, I don’t know if those subtokens would be useful.
Inside the extension grammar, I cordoned off the Action Analysis Engine from the rest to make it easier to work on (or eventually disable).
I’ve also hard-coded a number of functions in the Standard Prelude like zeroExtend according to whether they’re pure functions or perform an action, just for places where the context isn’t enough. If I ever integrate a Bluespec language server, I would probably move that hard-coding away from the grammar and into the language server. The server would maintain sets of each identifier according to what it is: struct, state-changing method, or what-have-you.
I really do think the Action Analysis Engine will help people debug. I haven’t run formal user testing on students new to hardware design or Bluespec, but I figure it’ll either help them learn or it’ll be awfully confusing. I’m hoping it’s the former.
External Consistency
A major benefit to syntax highlighting on VS Code is that the themes can cover many languages in a way that is useful for developers working in more than one language. That property is what I learned in 6.104 as external consistency. The idea is that a designer should account for a user’s other experiences in informing how they interact with a new design.
In the classroom, external consistency in syntax highlighting is even more important because while students are likely taking other computer science classes, they’re probably using different languages in each class. It can help them context-switch when the tokens of their Bluespec, their Python, their Java, and their C are all styled similarly in the editor. No matter the language, a keyword should look like a keyword, and so forth.
To take advantage of external consistency in a syntax highlighter, the grammar (which is what I wrote) needs to assign tokens according to their semantics. For example, enums in Bluespec should be assigned the same tokens as enums in C.
There are, of course, some constructs in Bluespec that don’t have exact equivalents in other languages. The whole idea of actions versus purely functional is something foreign to mainstream languages that I’m familiar with, though I would guess it’s got a parallel in functional languages like Haskell.
Where things don’t have exact matches, I make approximations. I figured Bluespec interfaces were most closely related to classes like in C++ or Java. I used the function token quite heavily, the same way that many other syntax highlighters do, and I used it for showing actions in my Action Analysis Engine.
There are situations where the tokens are styled similarly by themes, but the underlying tokens are actually distinct from each other. The way it works with the VS Code syntax highlighting is that, similar to CSS, there are selectors that are styled according to specificity. You can provide more detail in the form of subcategories, but the theme may only cover the major categories.
One example is _ACTION, _VOID, and _DONT_CARE, which are defined in my macro file like this:
#define _ACTION constant.language.action.bluespec
#define _VOID constant.language.void.bluespec
#define _DONT_CARE constant.language.dont_care.bluespec
A theme will probably color all these the same according to constant.language or even constant, but a dedicated theme could pull them apart. At the very least, using different tokens helps with debugging the extension.
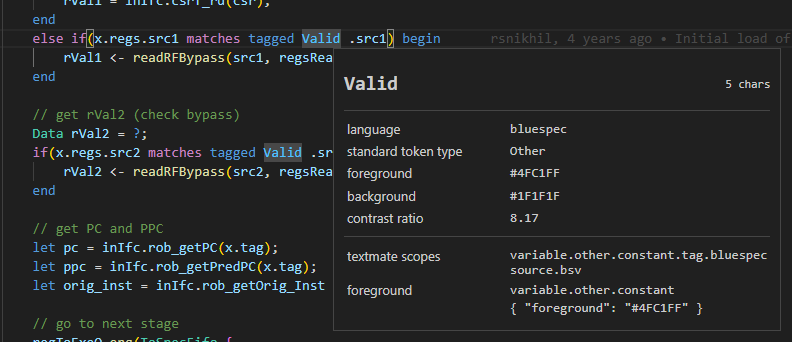
Valid is tokenized as variable.constant.tag.bluespec. Its proper name in Bluespec is something like a tagged union tag.Markdown Support
On version 1.1.2, I implemented injecting the Bluespec grammar into Markdown so that Bluespec is styled appropriately inside of Markdown fenced code blocks. It’s especially helpful for people like me who write posts or pages with Bluespec in Markdown (in VS Code). It can come in handy for educators preparing pages for their students, or students writing project reports.
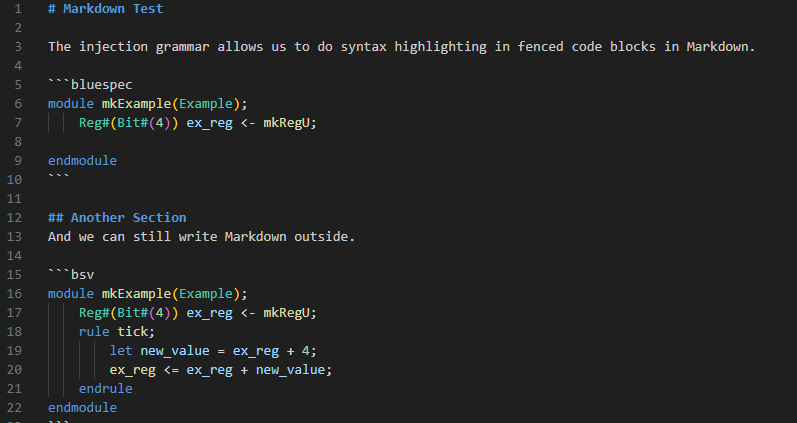
.bsv files. Just in case, I’ve also added support for minispec blocks.Process
Taking lessons from my Bluespec lexer for Rouge, I systematically built up a good set of rules for the grammar. A complex syntax highlighter can get very messy very quickly. That level of care is what makes this syntax highlighter even better than the one I made for Rouge.
The underlying lexing engine for VS Code is TextMate. Its framework for achieving state is a little different from Rouge’s. There’s no explicit state stack, but the “pointer” for rules is allowed to jump around using the TextMate rule constructs.
A fundamental difference is TextMate’s lexer uses two very particular types of rules for primitives. One type does only single-line regex matching, which is how we match most tokens. The other type matches a begin pattern, and if it matches then we enter its body until we hit the end pattern. It’s a powerful primitive that allows us to emulate state even if we don’t exactly have it (though not perfectly; it won’t recognize if we’re in one nested arrangement versus another nested arrangement), but it’s easy to mess up. There are a few parts of my code that don’t use them properly.
Another major difference is that while lexers for Rouge are written in Ruby, a high-level language, grammars for TextMate are written in JSON. There are many constructs available in Ruby that aren’t available in JSON.
Preprocessor
Computers love to parse JSON, but for people, they’re unsightly to either read or write. Early on, I took the VS Code Syntax Highlight Guide’s advice to write in YAML and convert it to JSON as part of a build process. Even so, the process was still tedious, especially because neither TextMate or YAML have the capacity to store variables.
Using variables for things like LOWER_IDENTIFIER was a big part of managing complexity while writing my lexer for Rouge. In the case of TextMate, the tokens were also long, and I had little inclination to write variable.other.constant.enum.bluespec over and over.
As such, I made heavy use of the C preprocessor, which allowed me to use C macros. I would work from a “raw” YAML that used macros, then I would convert into a legal YAML, and then into JSON. I stored long expressions as C macros so it’d be easier for me to parse through my own rules.
Still, the syntax highlighting available for writing the regexes in the YAML was nonexistent, making it a little difficult to know when I messed up a rule other than not seeing it execute. I thought it’d be too close to yak shaving to write a regex syntax highlighter to help me write a Bluespec syntax highlighter. In retrospect, it probably would’ve saved me some time. But I eventually just got really good at writing regexes.
With the C preprocessor and YAML, I could turn something like this:
conditional: # rather abstract rule
begin: (?x)
(?<=
(?:if |
rule.*(LOWER_IDENTIFIER)
)
)
(?:\s*\()
end: (?x)
(?:\))
patterns: # short-circuit from context
- include: '#always'
- include: '#dot_read_all'
- include: '#tagged_tag'
- name: _ENUM
match: (?<!tagged\s+)(UPPER_IDENTIFIER)(?!\s+(LOWER_IDENTIFIER))
- include: '#remainder'
- include: '#catch_error' # catch-all
into this:
"conditional": {
"begin": "(?x) (?<= (?:if | rule.*((?:\\b_?[\\p{Lower}](?:[\\p{Alpha}\\d\\$_])*)\\b) ) ) (?:\\s*\\()",
"end": "(?x) (?:\\))",
"patterns": [
{
"include": "#always"
},
{
"include": "#dot_read_all"
},
{
"include": "#tagged_tag"
},
{
"name": "variable.other.constant.enum.bluespec",
"match": "(?<!tagged\\s+)((?:\\b_?[\\p{Upper}](?:[\\p{Alpha}\\d\\$_])*)\\b)(?!\\s+((?:\\b_?[\\p{Lower}](?:[\\p{Alpha}\\d\\$_])*)\\b))"
},
{
"include": "#remainder"
},
{
"include": "#catch_error"
}
]
}
I was surprised that the VS Code guide to writing a syntax highlighter didn’t recommend anything past writing in YAML. I think the process would’ve been harrowing if I didn’t have access to C preprocessor macros. The difficulty is keeping a decent mental model of the entire syntax highlighter so that changes in one part don’t break another.
At the time of this writing, I used include 116 times and standalone name 79 times, making the lower bound of the number of rules a little less than 200. The overall grammar takes a tree-like structure, and if there’s one thing about tree-like structures, it’s that they don’t translate well to linear lists.
An overhaul of this grammar might be well-served by using a more sophisticated source than a C-preprocessor-enabled YAML file. We could take a look at what mainstream syntax highlighters use, because it’s probably not writing directly in JSON.
Testing
VS Code makes it easy to debug extensions. I had a Bluespec sample open on another screen and I would periodically refresh the extension to use the current version of the grammar.
It was my first time seriously using the VS Code debugger. Since I also needed to convert my raw YAML into legal YAML and into JSON, I put it all into a build script that was bound to Ctl + Enter. I hit the button, and the window refreshes with the new grammar. Super, super easy.
I’ll probably use the debugger again. Back when I was working on my processor, I was going into the terminal and running commands like a schmuck. Short commands that called scripts I wrote, but commands nonetheless.
Similar to when I was working on my lexer for Rouge, I first tested on my synthetic sample, then I tested on the most complex Bluespec samples I could find, which is currently RiscyOO/Toooba. I could test more effectively this time because I could open the entire repo in VS Code and go through every file and see how they looked. With Rouge, I had to paste into their visual test environment.
If I continued working on this, I would probably want a way to do automated testing, or at least start writing things down other than “eyeball it.” If you have ten rules, it’s easy to figure out if something is messed up. If you have two hundred rules, then something may break and only appear once in three files.
A middle ground less than automated testing but more than eyeballing large files is to write unit tests. That’s the original point of the synthetic sample, but I haven’t updated it to have all the corner cases that we might want to cover. Maybe I’ll update it next time.
Outreach
I think most students will find this extension on their own through the extensions Marketplace if they’re trying to use VS Code for Bluespec or Minispec. But I’m also going to reach out to educators who I know use Bluespec or Minispec as a teaching tool.
I’m quite proud of this extension, and it’s my experience as a student using crappy Bluespec syntax highlighting that encouraged me to make it. No student should have to go through that again.
Future Plans
If I continue using Bluespec into the future, I’ll probably continue improving this extension. If I drop it completely, then I’ll probably stop or only maintain.
I have grand plans if I do keep using Bluespec, including integrating semantic highlighting and implementing a Bluespec language server, but it’s a pretty big if. I don’t know anyone in the US using Bluespec professionally outside of academia, absent the people who are trying to promote it.
There are a bunch of quality-of-life changes that would make the extension better, like better snippets or IntelliSense.