Bluespec Lexer
github.dark, base16.dark, and gruv_box.dark. Want to see more? See how it processes more complex samples.- Overview
- Background
- Actions and State Changes
- Process
- Evaluation
- Next Steps
- Appendix: Installation
- Appendix: Known Issues
Overview
I wrote a Bluespec lexer for the Rouge syntax highlighter. Rouge is the default Ruby package for highlighting code blocks on sites generated with Jekyll, like this one.
This is a comprehensive, high-quality lexer that encompasses almost all of the Bluespec language. Its crowning feature is the ability to heuristically distinguish between state-changing and purely functional logic, a large part of debugging Bluespec.
The lexer can handle all levels of Bluespec complexity, including cutting edge open-source Bluespec. You can see the lexer at work on advanced Bluespec samples from the open-source MIT RiscyOO/Bluespec Toooba, including its scoreboard, MMIO, and prefetcher. I also have a page rendering my (considerably less advanced) home-made sample.
The source code is available on my fork of Rouge in two pieces: the lexer itself and the Bluespec sample I used to test, which is also rendered on this site.
I also prepared a list of known issues that tracks outstanding issues with the lexer or the test coverage.
Until I formally submit a pull request to try and merge my lexer into Rouge, you can follow the instructions in Appendix: Installation to add my lexer onto your own machine. If there’s sufficient1 demand, I may later prepare it for submission to the Rouge open-source project so it can be automatically available to all Rouge users.
I also discuss next steps now that I’ve prepared this lexer. I plan on using this experience to write the first halfway decent Bluespec syntax highlighter available for Visual Studio Code. [Edit: which I did!]
If you find an issue with the lexer, please feel free to reach out to me by Signal or email.
I hope you enjoy it!
Background
One of the reasons why I made this site was to present excerpts of Bluespec code in blog posts and projects. There’s a built-in syntax highlighter in Jekyll called Rouge, but Bluespec2 isn’t one of the supported languages.
I thought, well SystemVerilog is kind of like Bluespec syntactically; maybe I could just use that. In SystemVerilog, using the verilog tag3:
interface SomeBufferInterface;
method ActionValue#(SomeItem) remove_item; // removes and returns item from buffer
method Action add_item(SomeItem item); // adds item to buffer
endinterface
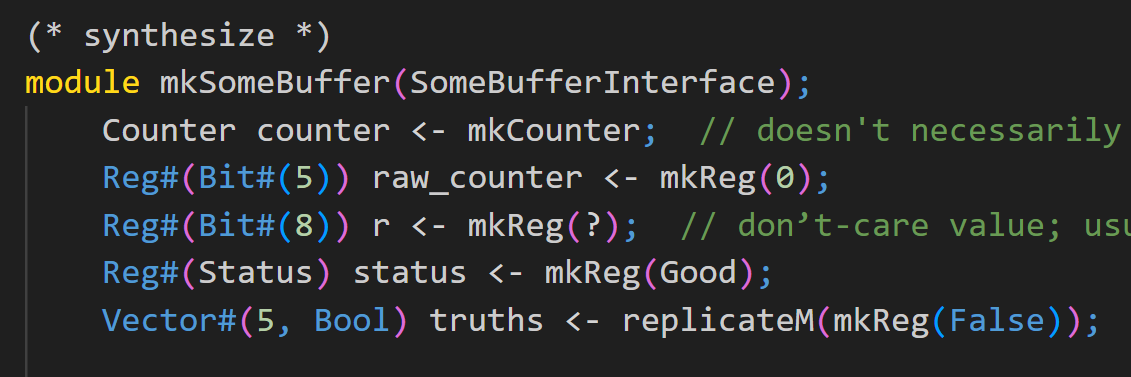
module mkSomeBuffer(SomeBufferInterface);
Counter counter <- mkCounter; // doesn't necessarily need to be named counter
// etc. other state
rule tick;
$display("Counter is at %0x", counter.value);
counter.incr;
endrule
method ActionValue#(SomeItem) remove_item if (counter.value != 0);
let item <- some_removal_action;
counter.decr;
return item;
endmethod
// etc. other methods/rules
endmodule
It highlights some keywords, alright. But you’ll notice it’s very bare. The highlighting is only slightly better than presenting my code in black and white.
I firmly believe that code must be readable, and that readability now includes using sophisticated syntax highlighting, especially in this age of VS Code. If I’m writing Bluespec in 2023, then I’m presenting it using 2023 standards.
Because I wanted high-quality (or at least decent) syntax highlighting for Bluespec on my website, I needed to write it myself.
Market Research
My lexer isn’t the first Bluespec syntax highlighter to exist, but it does a lot better than all the other syntax highlighters I’ve seen. And to my awareness, it’s the first one for Rouge.
The three main syntax highlighters of significance that I’m aware of are all rather bare.
- Two on VS Code: one small and mediocre and one mainly for Verilog with a Bluespec afterthought (really not very good)
- Sublime Text highlighter, used in GitHub rendering of Bluespec code, like in this sample from MIT CSG. One step above monochrome. Though, the bareness might be from GitHub’s minimal theming.
There are some other Bluespec syntax highlighters that I’m aware of, but haven’t seen examples of.
- Bluespec Inc. has, at least internally, a syntax highlighter for each of Emacs and Vim, which they (I assume) generously lent to MIT’s 6.175 about a decade ago for educational purposes. I don’t know if they’re any good. There are no demos and I haven’t investigated further because I’m loath to use either Vim or Emacs in this year 2023.
- The Emacs highlighter has snippets from Steve Allen, who was (is?) an employee of Bluespec.
- The Vim highlighter was maintained by Hadar Agam at Bluespec and was last updated in 2006.
- A number of other highlighters for other editors. Nobody seems to like having viewable demos for their highlighters. It’s as if nobody wants anyone else using their tools.
Actions and State Changes
Let’s discuss the best feature of the lexer: the way it treats actions and state changes.
Bluespec is built on guarded atomic actions (or rules), which allow it to maintain correct behavior even when many rules fire concurrently. The rules of a design ultimately describe the behavior, and every rule is a composition of actions.
The crowning feature of the lexer is its ability to heuristically highlight actions. The lexer will distinguish between statements that are purely functional and statements that perform an Action or produce an ActionValue.
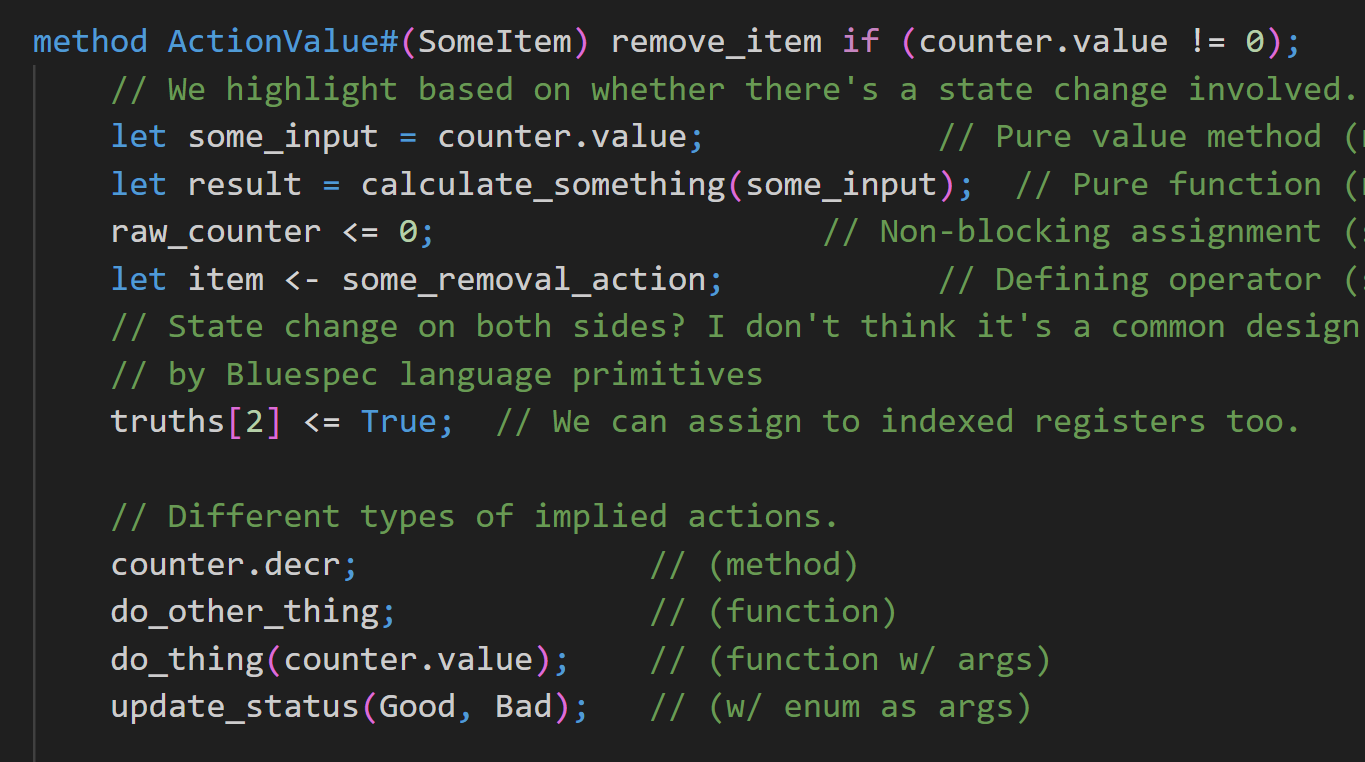
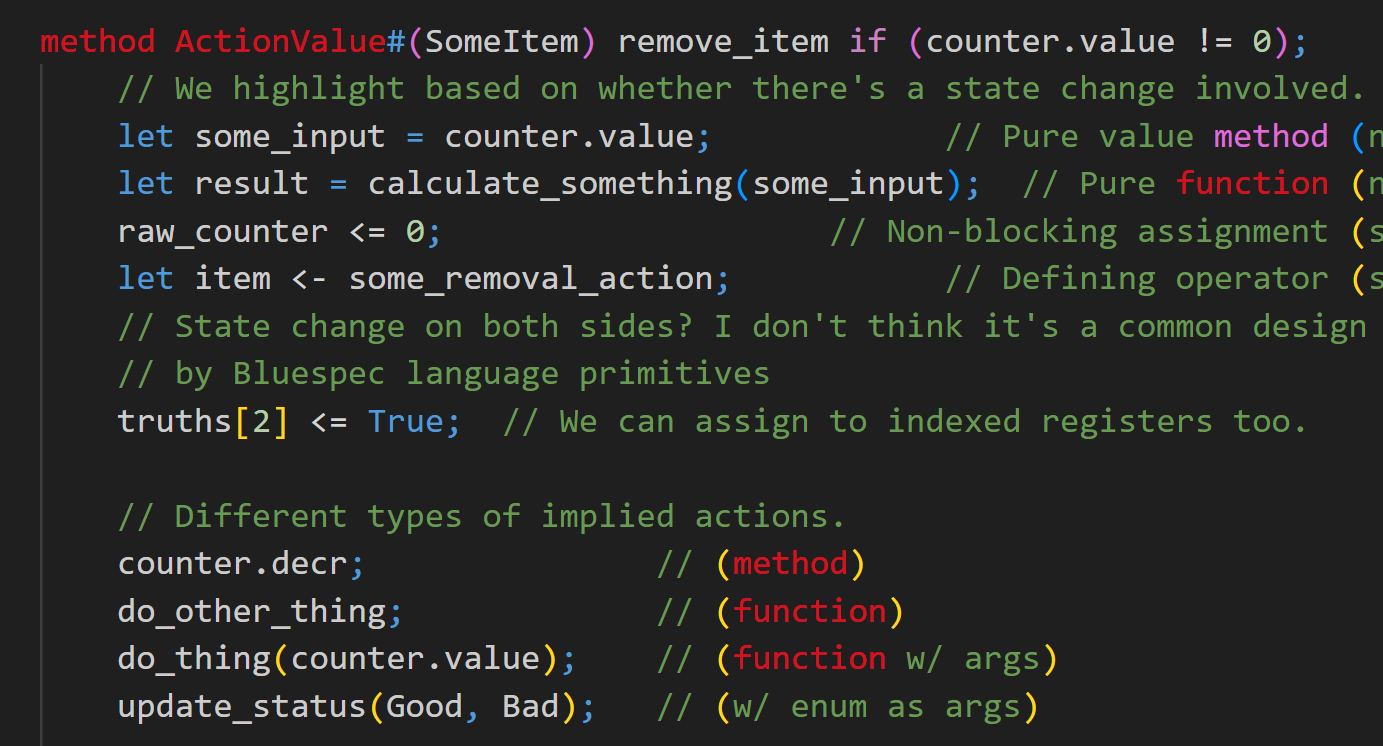
// We highlight based on whether there's a state change involved. (from my visual sample)
let some_input = counter.value; // Pure value method (no state change)
let result = calculate_something(some_input); // Pure function (no state change)
raw_counter <= 0; // Non-blocking assignment (state change on left)
let item <- some_removal_action; // Defining operator (state change on right)
// State change on both sides? I don't think it's a common design pattern, nor encouraged
// by Bluespec language primitives
truths[2] <= True; // We can assign to indexed registers too.
let some_output <- counter.some_actionvalue; // We can do ActionValue methods
// Different types of implied actions.
counter.decr; // (method)
do_other_thing; // (function)
do_thing(counter.value); // (function w/ args)
update_status(Good, Bad); // (w/ enum as args)
We can see at once where those actions are happening, whether they happen directly as methods of submodules or indirectly from inside functions.
Purely functional code, like the line let some_input = counter.value, won’t be changing any state. Its results may be used, but we can pay closer attention to exactly where those actions take place, which can be helpful in debugging for both correctness and scheduling.
The benefit of such highlighting might be limited for someone intimately familiar with their own code, or simple pieces of Bluespec. But what about code you’ve never seen before? What about readability for complex Bluespec projects?
Look at this rule from the RiscyOO/Toooba MMIO handler:
// handle tohost access
rule processToHost(state == ProcessReq && curReq == ToHost);
if(isInstFetch) begin
state <= SelectReq;
cores[reqCore].pRs.enq(InstFetch (replicate(Invalid)));
if(verbosity > 0) begin
$display("[Platform - process tohost] cannot do inst fetch");
end
end
else begin
let resp = MMIODataPRs {valid: False, data: ?};
if(reqFunc == St) begin
if(toHostQ.notEmpty) begin
doAssert(False,
"Cannot write tohost when toHostQ not empty");
// this will raise access fault
end
else begin
let data = getWriteData(0);
if(data != 0) begin // 0 means nothing for tohost
toHostQ.enq(data);
end
resp.valid = True;
end
end
else if(reqFunc == Ld) begin
resp.valid = True;
if(toHostQ.notEmpty) begin
resp.data = toHostQ.first;
end
else begin
resp.data = 0;
end
end
else begin
// amo: access fault
doAssert(False, "Cannot do AMO on toHost");
end
state <= SelectReq;
cores[reqCore].pRs.enq(DataAccess (resp));
if(verbosity > 0) begin
$display("[Platform - process tohost] resp ", fshow(resp));
end
end
endrule
There’s a complex control flow and a mix of non-blocking and blocking assignments woven in. But the highlighting makes it quickly clear where the state changes are happening: on state and cores[reqCore].prs, and sometimes on toHostQ. In a moment, we can set aside significant portions of the code that are purely functional, like the if(reqFunc == Ld) branch, and we can more quickly build our mental model of how this rule interacts with the rest of the module.
For Bluespec especially, whose very existence is to elevate developer productivity in hardware design, proper syntax highlighting (and that includes knowing where state changes are happening) lets us understand code better and quicker.
Performance and Scheduling
It’s important to distinguish between writing Bluespec for correctness, and writing Bluespec for performance. Ideally, we would like to do both, and indeed the promise of Bluespec is that the developer can mostly worry about the former and the compiler will handle the latter. But the developer is still given the freedom to write non-performant code.
If the developer wishes to write performant code, then they must take a closer look beyond state changes and actions. While reducing combinational path is a common approach to improving performance, here I discuss writing rules that can be scheduled well by the compiler. For this, I’m limited by the amount of state the lexing engine is allowed to command, so the developer must take a step on their own to figure out the scheduling implications of their rules.
One price of Bluespec’s correctness guarantee (given correct rules) is that the scheduler will detect (and separate) rules that conflict to prevent races. For example, two rules that each try to write to the same register will be prevented from firing in the same cycle.
While we can trivially achieve correctness by having every single rule fire in its own cycle (round-robin), such scheduling leaves a lot of performance on the table. We generally want rules that can conceptually fire simultaneously (e.g., the separate stages of a pipelined RISC processor) to do so simultaneously. We want as much concurrency as we can get without sacrificing correctness.
Writing hardware in Bluespec is a dialogue between the developer and compiler. The developer writes rules of what must happen in the hardware for correct execution, and the compiler schedules these rules to happen as often as possible without introducing race conditions.4
With careful design, some conflicting rules can be made not to conflict but still remain correct. In cases like this, the developer must carefully comb through their code and find the source of unnecessary conflict. While one source of conflict is from actions attempting to modify shared state, another source can even be from read-only methods.
Limitations
The biggest limitation is that the highlighting scheme only focuses on state-changing elements. When we’re trying to determine sources of scheduling conflict, we need to also think about read-only methods that have scheduling relationships with their sibling methods.
If a rule calls a read-only method with no impact on the state, it can still affect the scheduling. For example, take these two rules that act on two instances of state:
Unrelated unrelated <- mkUnrelated; // imaginary module with method `unrelated_method`
Example2R2W shared <- mkExample2R2W(False); // imaginary module with the below schedule
// search1 < search2 < write (schedule: earliest to latest)
// perhaps some internal rule happens between search1 and search2
// so that they aren't interchangeable; e.g., a bypass
rule tick1;
shared.write(shared.search1);
endrule
rule tick2;
unrelated.unrelated_method(shared.search2);
endrule
// resulting schedule on `shared` (^^^ for tick1, &&& for tick2):
// search1 < search2 < write
// ^^^^^^^ &&&&&&& ^^^^^ => therefore (NO GOOD: tick1 C tick2)
If we look only at the highlighting, we might assume it’s fine just because neither rule attempts to change the state of the same module. But these two rules tick1 and tick2 may never fire in the same cycle because they’re not serializable in a single cycle. Even the “read-only” shared.search2 in tick2 does not play nicely with tick1 because of the underlying scheduling.
Let’s say we want to patch this limitation, that we should account for read-only methods. Then, we would need to make additional hard choices. Syntactically, not much distinguishes a method call with no arguments from an access to a struct.
typedef struct {
Bit#(4) member; // guaranteed conflict-free (CF) w/ other accesses
} ExampleStruct deriving (Eq, Bits)
interface ExampleInterface;
method Bit#(4) member; // may be beholden to scheduling restrictions
endinterface
module mkExample(Example);
ExampleInterface ifc_instance <- mkExampleInterface;
ExampleStruct struct_instance = ?;
let var_1 = ifc_instance.member; // this is a read-only method call
let var_2 = struct_instance.member; // this is a struct member read
endmodule
Similarly, not much distinguishes a local variable read from a register read, or a local vector access from an EHR read (or for that matter, any method array access).
module mkExample(Example);
Reg#(Bit#(4)) some_register <- mkRegU;
Ehr#(3, Bit#(4)) some_ehr <- mkEhrU; // ephemeral history register
rule tick;
Bit#(4) local_variable = ?;
let var_1 = local_variable; // just a local variable; declared right above
let var_2 = some_register; // register read; usually won't impact schedules much
Vector#(3, Bit#(4)) local_vector = ?;
let var_3 = local_vector[2]; // local array; declared right above
let var_4 = some_ehr[2]; // EHR read probably *will* have schedule implications
endrule
endmodule
There are likely other similarly tricky scenarios. The lexer would require substantially more state in order to distinguish between these cases, on the order of semantic highlighting. It would need to maintain a list of variables and what they are, and it may need to do so even for large projects. Only then would we be able to accurately and usefully highlight between these syntactically identical cases.
An even more sophisticated semantic highlighter should be able to highlight according to schedules (maybe with the aid of the Bluespec compiler’s internals), allowing a developer to see schedule details before compilation proper. You can imagine mousing over a rule name in VS Code and seeing a list of rules it conflicts with, or mousing over a submodule instance and seeing its method schedule.
Both of these are possible, but it would take further research to figure out the best way to do it. In any case, these features are more relevant for development rather than presentation on a site. In the meantime, I decided highlighting only state-changing parts of the code was a good compromise.
Process
The Rouge lexer provides a well-written guide to lexer development. I also needed to dive directly into the RegexLexer class details and the list of tokens available.
Put simply, a lexer runs from the beginning of a text to the end, applying a set of regular expression (regex) rules and assigning from a set of lexical tokens to meaningful pieces. For example, I would often recognize something like Reg#(Bit#(4)) as an interface (or type), and I would encode it as a Name::Class. I kept a careful eye on matching text to the most semantically equivalent token available, which helps with the usability heuristic of external consistency.
The Rouge lexer also gives access to a stack of states, which I can push to or pop from upon encountering particular rules. It’s useful for things like when we know we’re entering a conditional or an assignment or when we’re distinguishing between actions and non-actions.
My lexer code, then, is a long list of regex rules and state transitions that tell the lexer what to do at each stage of the text. I admit it starts out neat and ends up messy. It was the first time I used regexes (or Ruby) for a significant task.
I began by (re-)reading and encoding the Bluespec Language Reference Guide available on the Bluespec repo. It walks through different features of the language and describes the grammar using a combination of extended Backus-Naur form (BNF) and plain English.
It became rather tedious after encoding the rules for literals, so I decided to use what I know of Bluespec and write the lexer using heuristics, rather than strict grammar. As I would later find out, it’s common for lexers to use mainly heuristics as a way of making sense of a text. I began with a simple Bluespec sample that tested very few features, then I alternated between adding more Bluespec features into my test and adding more rules into my lexer to cover those features. Call that incremental build. You can find the current iteration of my visual sample here.
We often don’t need the fidelity of a full abstract syntax tree to properly highlight. That level of specificity is only required for code generation. But the closer we can get to the grammar, the more sophisticated our lexer can be. I would consider what I have to be about 95% sophisticated and 5% dumb, since we do use a fair number of state transitions. I’m tracking the remaining known issues.
A point of difficulty is that there’s also not a strict mapping between the formal grammar and the tools I had in the lexer development. A grammar is described in terms of non-terminals, often with branching. I had access to a bit of branching in Ruby, but to fully take advantage of the grammar would require introducing a lot of state onto the stack and some unintuitive design patterns. I’m convinced that’s what it takes to have a truly phenomenal, cream-of-the-crop syntax highlighter, but I think a highlighter used mainly for code presentation and reading need not be as advanced as a highlighter used for editing.
When I write a syntax lighter for VS Code, I plan on using every tool at my disposal to have that truly phenomenal syntax highlighter. A 21st century HDL requires a 21st century syntax (or semantic) highlighter. [Edit: See the syntax highlighter extension I ended up writing!]
As I progressed, I began learning about and taking advantage of more sophisticated techniques for lexing. I started with a stateless implementation, then I began using the state stack and regex features like lookaheads and non-capturing groups. I probably would benefit from using backreferences and other features too, if I wished to refactor my earlier regexes.
When I couldn’t think of what to test next, I would draw from parts of my source code for my superscalar processor as a reminder of the Bluespec features I used. That got me pattern matching and struct unpacking, as well as a bunch of other things.
Once I had what I was sure was a fantastic lexer, I brought in some existing Bluespec from the MIT RiscyOO/Bluespec Toooba project to further test my lexer. These samples had much higher complexity than what I wrote, and they would also have correct Bluespec that was stylistically different from mine, helping me patch edge cases. These samples represent the pinnacle of open-source Bluespec. If my lexer could properly highlight those, then they could highlight anything.
In terms of development time, the first 15% of the process gave a highlighting quality better than what I found on the Internet. The other 85% was spent ensuring coverage of Bluespec features, proper testing (including regression testing), and generally making sure that the resulting syntax highlighting was as top-notch as the syntax highlighting from a mainstream language like Python, C, Java, or JavaScript.
Evaluation
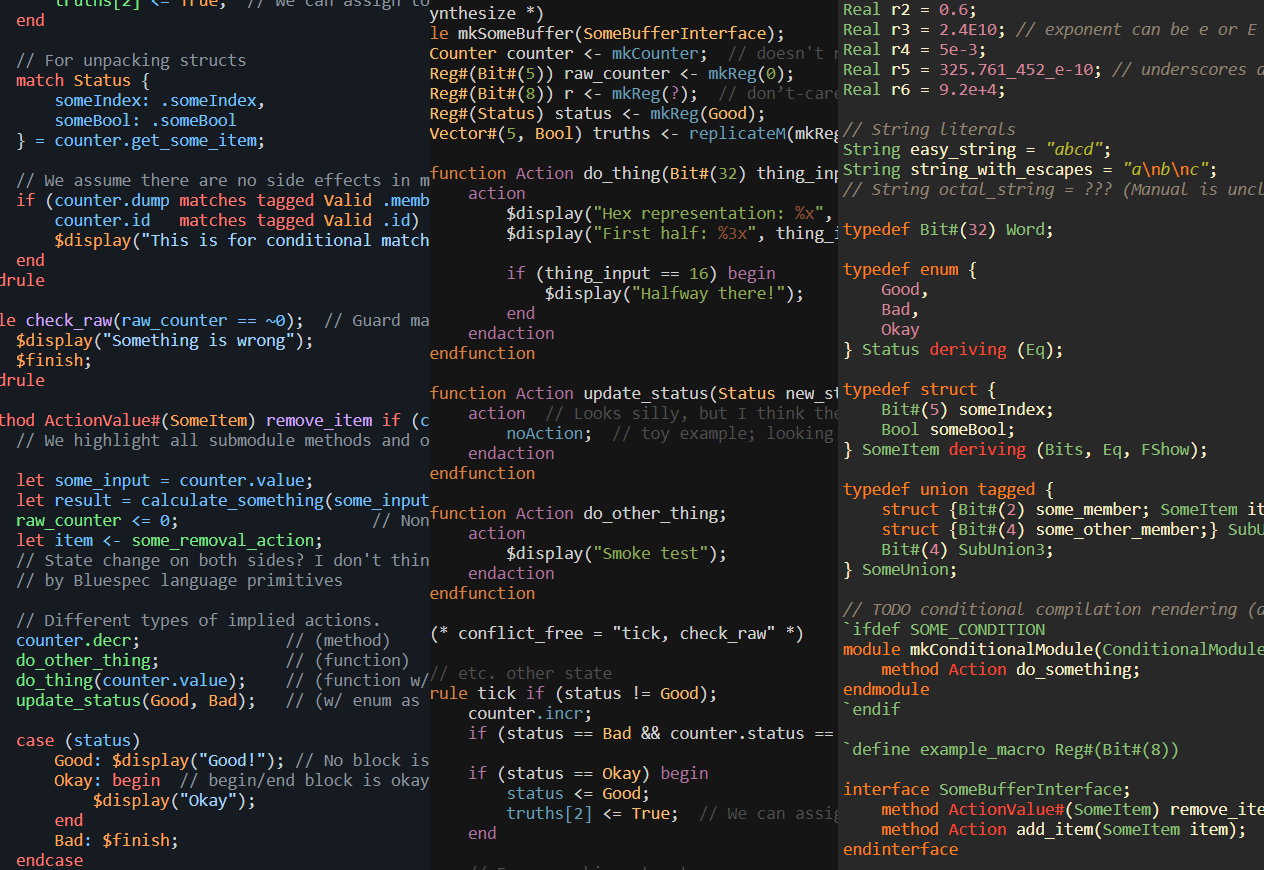
There’s no better way of evaluating a lexer5 than by seeing for yourself what it can do. Take a good look at any of the samples below.
The default syntax highlighting theme on Jekyll’s Minima (at least for dark) is rather unappealing, so I imported CSS derived from the github.dark theme used by the Rouge tester, with minor modifications. If you find the theme too saccharine, you can always theme it differently yourself with any number of publicly available syntax highlighting themes (or make one yourself).
From excerpts of the open-source MIT RiscyOO/Bluespec Toooba project:
And my modest home-made sample.
Next Steps
My next step is to write a syntax highlighter for VS Code using everything I learned about syntax highlighting from this project. [Edit: which I did!]
The funny thing is, I set out to write a Bluespec lexer for Rouge only because the Bluespec syntax highlighting on Jekyll was nonexistent. On VS Code, I had an okay syntax highlighter in the sense that it only recognized keywords, system tasks, literals, punctuation, and comments. It had major deficiencies when it came to user-defined elements, but at least it did something.
The VS Code highlighting was decent enough that, as described by the region-beta paradox, it didn’t seem worth it to put in the effort to rewrite or improve it.
Now that I’ve had some practice with writing an excellent lexer for Rouge, I feel much more confident about my ability to write not just a decent, but phenomenal extension for VS Code, which has a different format for lexers but provides a nice guide on writing grammars for their syntax highlighting. You can expect another post (or series of posts) from me on the process. [Edit: like this one.]
VS Code has had a meteoric rise in popularity since 2017, and according to Stack Overflow, it’s what 3 out of 4 developers (including me) use. That proportion has been true for three years straight. You can bet that the vast majority of new Bluespec users, at least those originating from college, are using VS Code.
I suppose I can also work on snippets and other useful features. But I think syntax highlighting must come first. The saying goes that code is read far more often than it is written. Now that I’ve seen what syntax highlighting can do, I don’t think I could touch another line of Bluespec without it.
When I get far enough along on the VS Code extension, I’ll see about refactoring my Rouge lexer. Hemingway said, “The only kind of writing is rewriting.”
Appendix: Installation
If you also want to have nicely formatted Bluespec excerpts on your Jekyll site, or if you want to highlight Bluespec using Rouge, you’re in luck. I haven’t yet submitted a pull request for submitting my lexer to Rouge, but you can still use my lexer for your own installation of Rouge.
Simply clone the Bluespec branch of my repo of Rouge in your chosen directory with either
- (SSH)
git clone -b feature.bluespec-lexer git@github.com:mchanphilly/rouge.git - (HTTPS)
git clone -b feature.bluespec-lexer https://github.com/mchanphilly/rouge.git
Then in your Jekyll site’s Gemfile, put a line that directs your rouge gem to wherever you put the repo. In my Gemfile, I have my Rouge as a sibling folder to my website directory, so for me I have
gem "rouge", path: "../rouge"
At this point all you need to get Bluespec highlighting on your website is to write Markdown code blocks as usual but with the bluespec or bsv tags. It would look something like this:
## Example Subheading
Something something here's some code:
```bluespec
module mkExample(Example);
Reg#(Bit#(1)) some_state <- mkRegU;
rule tick;
some_state <= ~some_state;
endrule
endmodule
```
Something something explaining the above code [...]
For inline code highlights, you can do the following (I’m not sure if there’s a better way):
`module mkExample(Example);`{:.language-bluespec .highlight}
and it’ll appear like module mkExample(Example);.
You can either use the default Jekyll theme for highlighting, or you can add your own CSS to do the theming.
Personally, I didn’t like Minima Dark’s code highlighting theme, so I added CSS to my site that adapts the github.dark theme that Rouge tests use from the Rouge theme (written in Ruby).
If you want to use what I use, make (if there isn’t one already) a _sass\minima\custom-styles.scss in your Jekyll site directory, and add in the line @import "./rouge-github";. Then download the CSS stylesheet and place it into the same directory (so it should be _sass\minima\rouge-github.css). Now, it should be ready to go.
If there’s enough interest, I could write a script that could do all of the above for you. Let me know if you have any trouble with it.
Appendix: Known Issues
- When a
returnstatement is attempting to return a module implementing aninterface, neither methods nor functions used inmethodorruledefinitions in that module will be recognized as state-changing. The lexer assumes noActiontakes place on the right side of an assignment or return. A fix would be to lift that assumption if we’re in aninterfaceinside of areturn, but we would need to crawl the entire state stack. I would need to carefully test to make sure any fix doesn’t have bad side effects.return (interface SbLookup; method RegsReady get(PhyRegs r) = unpack(0); method Action remove(Maybe#(PhyDst) r); sb.remove; // This is an Action. endmethod endinterface); - When we use shorthand assignment for
methods orfunctions, the lexer assumes that any calls on the right side will change state. We can fix this by using state when there’s an explicit return; if the return type doesn’t specify anActionorActionValue, then we can assume there’s no state change on the right side. If the return is implicit, we would require the lexer maintain more state than we have access to, requiring a stronger tool (i.e., semantic highlighting.)module mkExample(Example); method Bool do_thing = counter.ready; // explicit return type; method call method do_other_thing = ready; // implicit return type; function call // Something our lexer does do well is lex incomplete code; e.g., no endmodule - We don’t properly process identifiers that aren’t strictly conforming to the casing convention. Some flexibility can be good so that our lexer doesn’t break just because a developer decides to case differently, especially if the compiler accepts it.
module mkbad(bad); // assuming the compiler allows this (by memory) - We need to test shorthand rule declarations. I suspect there may be issues with the
=assignment operator, if that exists for rules. - More generally, I need to parse through the Bluespec SystemVerilog Reference Manual for obscure features that I might not be familiar with.
- One example is type annotation, either at the end of a module declaration or in types to nudge the compiler. Things like that, where not everyone uses those features but it’s nice to patch up the corner cases for the people that do.
- In my move fast and break things phase of lexer development, I’ve inadvertently introduced quite a bit of spaghetti code in the lexer. It’s difficult to parse through without intimate familiarity (like I’ve developed). It could do with a refactor. This issue isn’t directly visible to the user, but just for me and anyone else who decides to look at the lexer source.
- Rearranging the rules can also help reduce lexing time, but that’s a compilation-time issue that frankly isn’t high priority. What difference is a factor of two, three, or even ten when we’re lexing in less than a second? Lexing performance matters more when we’re editing the code live, but less when we’re compiling into a page.
- We can make cosmetic changes in comments that make them more readable.
// Maybe comments should have formatting. TODO (keyword highlighting) /* Maybe we can have something like *italics*, or **bolding**, or ~~strikethrough~~, or (advanced feature) even internal links */
-
e.g., if there’s more than like 10 people interested. I suspect right now there’s only me. ↩
-
The number of people who write online Bluespec content is probably in the single digits, if not zero. ↩
-
On the list of Rouge lexers, Verilog support is described as “verilog: The System Verilog hardware description language,” which doesn’t seem quite right. There’s no separate Verilog/SystemVerilog. ↩
-
The developer can reach over to the scheduler’s side with directives like
(* mutually_exclusive *). Ideally, we should be offloading scheduling work to the compiler, and I assume that’s what the folks working on the Bluespec compiler are working on. ↩ -
You can also evaluate a lexer by the quality of its code, and I admit at the time of this writing, it’s gotten quite messy. I may write a separate post about the development process later. ↩