Write-After-Write Bug
A technical blog post describing the write-after-write bug I found in my processor project.
Introduction
The minimal out-of-order processing in my processor project has a bug that I didn’t catch until now. Not only is the out-of-order processing minimal, but it isn’t even fully correct because it ignores write-after-write (WAW) hazards.
Most of the time, it isn’t an issue, and in fact I didn’t catch it with existing tests, but we can write a sequence of instructions that result in our processor giving the wrong answer. It’s the specific case where instructions are sliding past each other but we write to the same destination register in the wrong order.
In this post, I write a test case that demonstrates the write-after-write (WAW) hazard. To make the out-of-order part correct, I would need to either add in proper reordering or induce more stalls for when out-of-order commits may produce incorrect results. I’ve plugged this post into my project write-up as a correction.
Background
I found the bug while reflecting on a recent job interview where I was discussing my processor project. It was the first time I had the opportunity to talk about my project’s out-of-order-ness in any detail with anyone else, let alone an engineer in the field. It’s not the best of circumstances to find a bug, but it’s probably better than finding a bug post-fabrication.
In my processor, the register-read stage induces stalls so that instructions wait for their source registers to be ready (solving read-after-write hazards), but not for their destination registers to be ready. This was perfectly fine when every instruction would complete in order, but we end up with write-after-write hazards when instructions commit out of order and those instructions write to the same destination register.
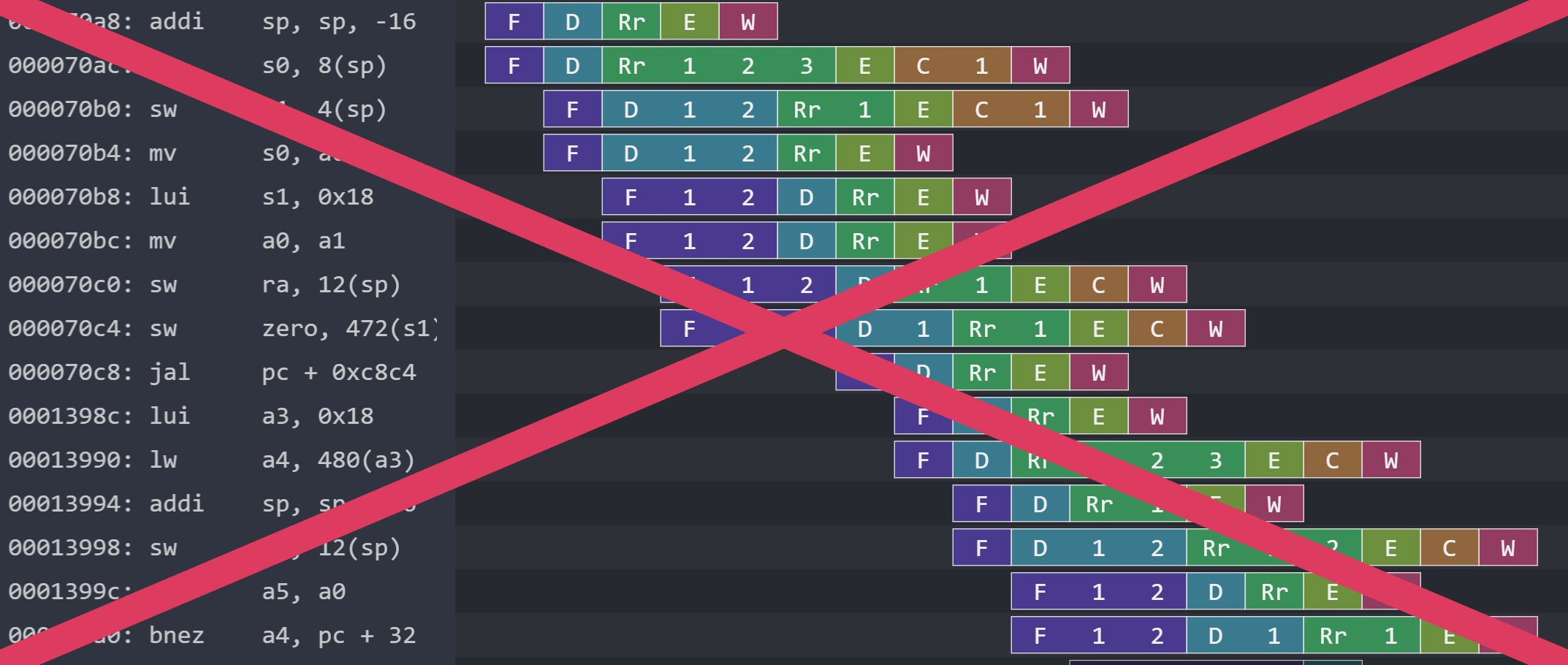
It’s a little embarrassing that I plastered these pipeline visualizations all over my write-up that might look obviously wrong to an expert at a glance, but in context it’s not too too embarrassing. I only ever learned about out-of-order processing on my own during the summer, and it’s hard to get feedback when I don’t have instructors or office hours to draw on like I did for things I learned in class. If I was doing this for school, it would’ve been caught in office hours or after turning in an assignment, or I would’ve been reminded during lecture. It just so happened that I was reminded recently during a job interview.
I do recall a case during office hours last semester when I showed my professor Thomas a visualization where the instructions appeared to be committed out of order. He expressed concern then, like it wasn’t supposed to happen. In that case, I knew it was just because of a bug in my Konata instrumentation, not really the functionality of the processor itself.
I discounted the out-of-order commits when working on the project during the summer because I was expecting my processor to be doing some things out of order. I just forgot this was a case that might give incorrect results. I probably could’ve caught it myself earlier if I had been more careful with the design or did a closer reading of Hennessy and Patterson during the summer while I was self-studying.
This and similar bugs might be more obvious to me if I had more experience with sophisticated out-of-order processors like the MIT RiscyOO project or during study before attempting to implement similar features myself. On the other hand, I might not have internalized the lesson as well if I didn’t find the issue in a firsthand project like this one. It’s hard to say!
Deficiency in Existing Tests
I didn’t set up a unit test for write-after-write, but I am a little surprised my integration tests didn’t catch the issue. I can think of some reasons why.
My main guess is that the degree of out-of-order processing in my processor was so limited that the bug just didn’t show up in my tests. That, and my integration tests might just be too small for the issue to show up anyway.
The criteria for the bug to appear is where we have two instructions that write to the same register and were given permission to slide past each other during the register read stage. The only case that this would happen is when it’s happening across two separate functional units, like the ALU functional unit and the memory functional unit.
Because my processor’s instruction window was something like 2-3 instructions (very modest compared to the dozens or hundreds of instructions in high performance processors), and because all instructions spend only 1 cycle (in the case of ALU) or 2 cycles (in the case of memory) in execution, it was rare that I would have two instructions at the head of their respective queues that want to write to the same register.
Equivalently, I think the bug maybe would’ve shown up if the instruction window was wider or if the execution stage took longer. Either implementing my improved instruction issue buffer or lengthier functional units like a multiplier or floating point unit maybe would’ve caused the issue to appear.
Furthermore, most of my test cases were simple C programs optimized using GCC’s O2 optimization flag. We saw previously that the compiler would rearrange our instructions in such a way that we could maximize use of instruction-level-parallelism, such as when we needed to save registers to the stack.
One of these optimizations may be that the compiler tries not to give us instances where two nearby instructions try to write to the same register. Sometimes that isn’t an option due to restrictions in RISC-V calling convention, but my instruction issue window is so small and my test programs are so simple that it just wasn’t an issue.
I had more tests available to me through RISCOF, but I had stopped supporting it when I migrated the processor from a rigid execution pipeline to the flexible functional unit set-up. I wonder if those tests would’ve caught them. I would need to re-add support to find out.
Test Case
We can write a test so that we can see that the issue truly exists and, when we eventually fix it, to help verify that we fixed it.
Conceptually, we want to store to a register in two consecutive instructions, one that goes through the ALU functional unit, and another that goes through the memory functional unit. We might later also want coverage to check that our two ALU functional units don’t also display the WAW hazard, e.g., if we have two consecutive li to the same register. But let’s start small.
In C, the test might look like this:
int main() {
int a;
a = 1;
a = 0;
if (a == 0) {
exit(0); // test passed
} else if (a == 1) {
exit(1); // test failed because we used the old value of `a`
} else {
exit(2); // test failed for another reason (maybe `a` is uninitialized)
}
}
For the sake of this test case, I’m going to write it directly in RISC-V. I don’t know if the case I described is something that a compiler would produce from C code, but I do know the situation in RISC-V assembly where it could happen.
All of my existing tests are complied from C. This new test doesn’t exactly fit into my testing framework as-is, since it’s not doing any of the MMIO to indicate whether the test passed or failed. Instead, I’m judging visually from the pipeline visualization. It would take a bit more boilerplate before I could integrate it into my existing battery of correctness tests for automated testing.
Still, I want to do a quick mockup to illustrate the issue. The following test should fail with our current design. A pass should result in a forward branch, while a fail should result in no branch.
In practice, I don’t think a compiler would ever generate code like this. In this mockup, the lw a0, 0(sp) is dead code because the value is never used before the following li a0, 0. A compiler would probably remove it altogether (though maybe not with the O0 flag). But this arrangement is useful to isolate the bug, since it’s a very short sequence of instructions.
; I'm using ';' because the Rogue syntax highlighter only supports NASM assembler
test:
; these two instructions put 1 into 0(sp) (it might violate calling convention)
li a1, 1
sw a1, 0(sp) ; save 1 to 0(sp)
; these instructions both use a0 as a destination. The second should overwrite the first.
lw a0, 0(sp) ; load 1 to a0 (from memory)
li a0, 0 ; load 0 to a0 (from immediate)
beqz a0, pass ; branch to pass if a0 is zero (otherwise continue to fail)
fail:
li a0, 1 ; kind of like the exit(1); we fail
unimp ; repeated several times for cosmetic reasons (processor exits)
pass:
li a0, 0 ; kind of like the exit(0); we pass
unimp ; repeated several times for cosmetic reasons (processor exits)
The test should go to pass, executing li a0, 0 and unimp, which triggers an exit on my processor. But I believe with my implementation that the beqz instruction is going to use the lw value instead, causing the test to fail.
And indeed it does fail, corresponding to Frame 2 of the following animation. We should be getting a result similar to Frame 3, where we exit with 0 in a0 after a forward branch.
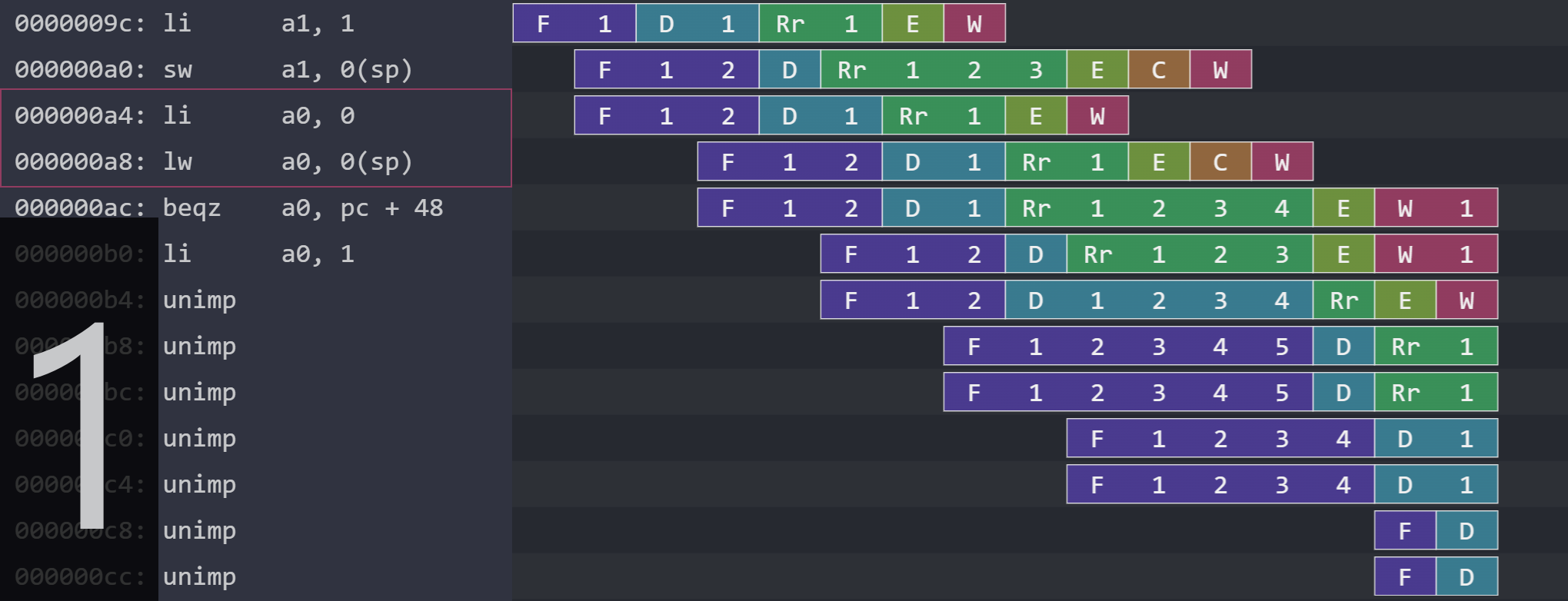
li-lw, lw-li, and nop-li cases respectively, which differ only in the instructions at pc a4 and a8. We should certainly not get the same results in Frame 2 as in Frame 1.This animation uses three different pairs of instructions to set the value of a0. Going frame by frame, this is what’s happening:
- Frame 1 has
li-lw. It’s true that thelicommits earlier than it should, but it doesn’t mess with the correctness of the program’s output because the value fromliis never used before being replaced by the value fromlw. In this case, the bug is benign. - Frame 2 has
lw-li, corresponding exactly to our assembly test case above. Our processor gives the wrong result, since it should branch but doesn’t. - Frame 3 has
nop-li. We branch because we loada0with theliinstruction only, without anlwinstruction.
When I say the result is correct or not, I’m only looking at the value we get at the end of the test. In reality, the state of our processor for all three frames can be incorrect if you stopped it at particular cycles because the register file and memory are updated as soon as the W stage concludes for a given instruction. In more sophisticated processors, they might require changes to the processor state to occur in the correct order through something like a reorder buffer. We don’t currently worry about interrupts or traps, so the out-of-order commits can be benign.
Looking at the visualizations, it’s no mystery why both orderings of li-lw and lw-li behave like li-lw with our processor. In lw-li, while lw is waiting on the previous sw to complete, our processor (mistakenly) allows the li to slide before the lw. The value that ends up in a0 is therefore the one entered by the lw instruction, even if lw was supposed to happen before li.
Another Hint
Another hint that my processor was bugged is that the Konata pipeline visualizer doesn’t really support instructions committing in the wrong order, as if it expects in-order commits. It looks fine when I make my visualizations without hiding flushed operations, but the bug appears when I do hide flushed operations.
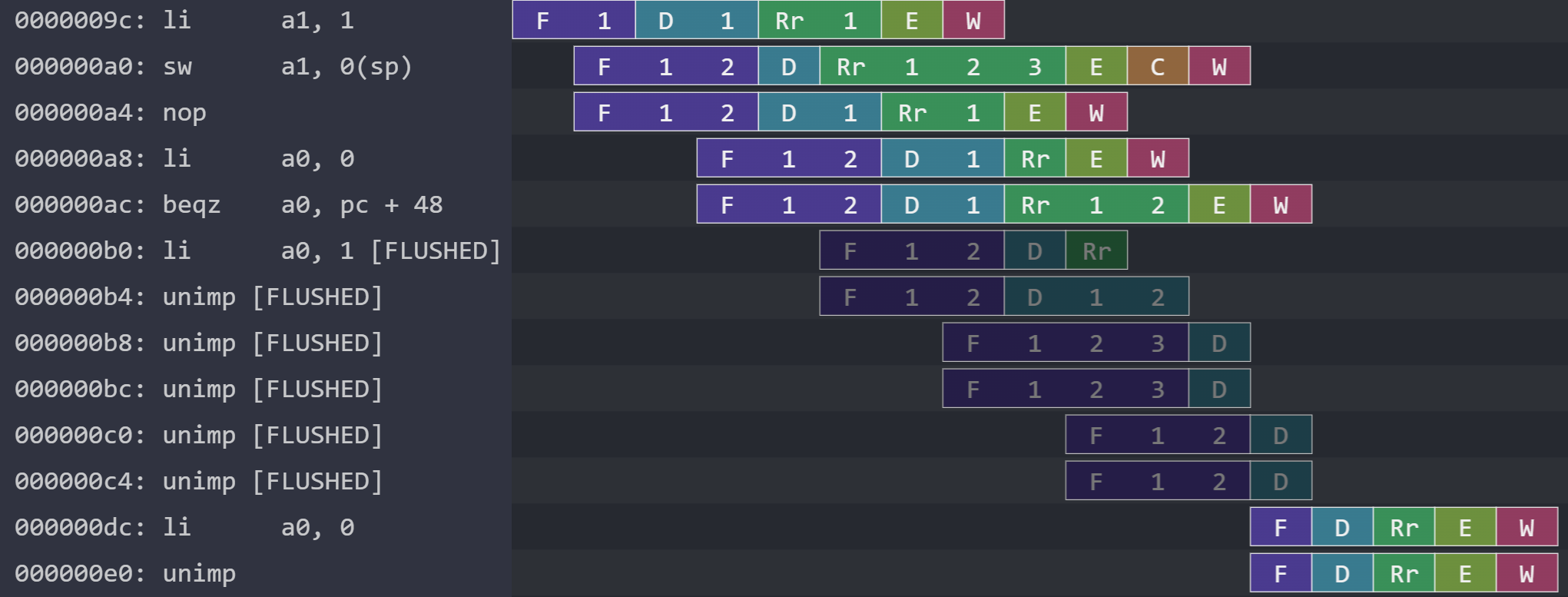
nop-li case with flushed operations shown and hidden.Hiding flushed operations makes Konata sort the instructions by when they commit. Because my processor has them (incorrectly) commit out of order, Konata “reorders” my instructions for me in the visualization.
Not only that, but Konata also removes the final li and unimp instructions. I think that must be because the processor terminates simulation in Writeback without the final Konata commits, which maybe were supposed to happen in a later cycle.
This also suggests that the way Konata measures whether an instruction is flushed might be by seeing whether it was committed to Konata, rather than seeing if it had been flushed per se. These are subtly different according to the Konata log format. The distinction only really matters in corner cases like this, since most of the time all instructions are either flushed or committed. These last two instructions just happened to have neither.
How do we fix it?
We have two main options for the fix.
- We can add in register renaming with a reorder buffer (like prescribed in Hennessy and Patterson) so we can execute instructions that use the same destination register without dependencies between the inputs. This is the harder fix but should make our processor more capable of bona fide out-of-order processing.
- For the reorder buffer, we could either use Bluespec’s
CompletionBufferpackage or write one ourselves. - I suspect the register renaming part would be tougher to implement, but maybe not so if I can find a decent strategy elsewhere. For all I know, there might already be an idiomatic implementation in Bluespec.
- For the reorder buffer, we could either use Bluespec’s
- We can introduce stalls so that instructions are stalled from issuing if their destination register is being used as an earlier instruction’s destination. It might slow down our processor but it should be a simpler fix.
- We would still be able to allow some out-of-order commits as long as they don’t affect the same destination registers.
- A more conservative fix would be to fully disable out-of-order issuing altogether, if you want to call that a fix.
Neither of these I can do in time for this week’s post, so I’ll defer it to some other time.